OpenAI блокирует злоупотребления ChatGPT из РФ, КНДР и Китая
OpenAI сообщил о прекращении работы нескольких групп аккаунтов, которые использовали ChatGPT для помощи в создании вредоносного ПО, фишинга, мошенничества и операций влияния. Среди задействованных кластеров — аккаунты, связанные с российскими уголовными группировками, северокорейскими операциями (связанные с Xeno RAT), китайскими группами, занимающимися фишингом и промышленным шпионажем. Компания также блокировала сети, работающие в Камбодже, Мьянме и Нигерии, использовавшие ИИ для мошенничества.
Что именно обнаружил и пресёк OpenAI (факты)
- OpenAI нарушил работу трёх крупных кластеров аккаунтов, которые использовали ChatGPT для помощи в разработке RAT, C2-инфраструктуры, создания фишинговых писем и разработки вспомогательных утилит (обфускация, мониторинг буфера обмена, exfiltration через мессенджеры).
- Первый кластер — русскоязычный: злоумышленники использовали несколько аккаунтов для итеративной отладки кода (разработка remote access trojan и credential stealer), публикуя доказательства в Telegram-каналах.
- Второй — северокорейский: операции, связанные с Xeno RAT и таргетированными фишинг-кампаниями против дипломатических миссий. Эти группы использовали модель для разработки macOS Finder extensions, VPN-конфигураций и подготовки вредоносных загрузчиков.
- Третий — китайский кластер: фишинговые кампании (англ./кит./яп.), инструменты для ускорения рутины (remote execution, TLS traffic handling), и поиск по репозиториям вроде nuclei/fscan.
- Дополнительно OpenAI блокировал аккаунты, используемые для мошенничества в странах Юго-Восточной Азии/Африке и аккаунты, предположительно связанных с наблюдением за религиозными меньшинствами.
Аналитика: почему это важно и что показывает кейс
1) Новая форма «инкрементальной» эксплуатации
Злоумышленники не требовали от LLM сгенерировать прямо вредоносный исполняемый файл — модель часто отказывала в прямых запросах. Вместо этого они запрашивали строительные блоки: фрагменты кода, утилиты, инструкции, которые затем собирали в рабочие цепочки. Это делает проблему более скрытой и сложной для детекции.
2) ИИ повышает эффективность разработки вреда
Использование ChatGPT позволило группам быстро прототипировать, дебажить и локализовать платформо-специфические приёмы (DLL injection, in-memory execution, API hooking). Даже если каждый блок полезен в целом, их комбинация позволяет получить полноценный эксплойтный инструмент.
3) География и тактика: смешанные сети злоупотреблений
Операции охватывают разные юрисдикции и тактики: от ransomware/RAT-разработки до influence-кампаний и мошенничества. Это указывает на мультиформатное злоупотребление ИИ: одни используют модель для технической помощи, другие — для масштабной социальной инженерии.
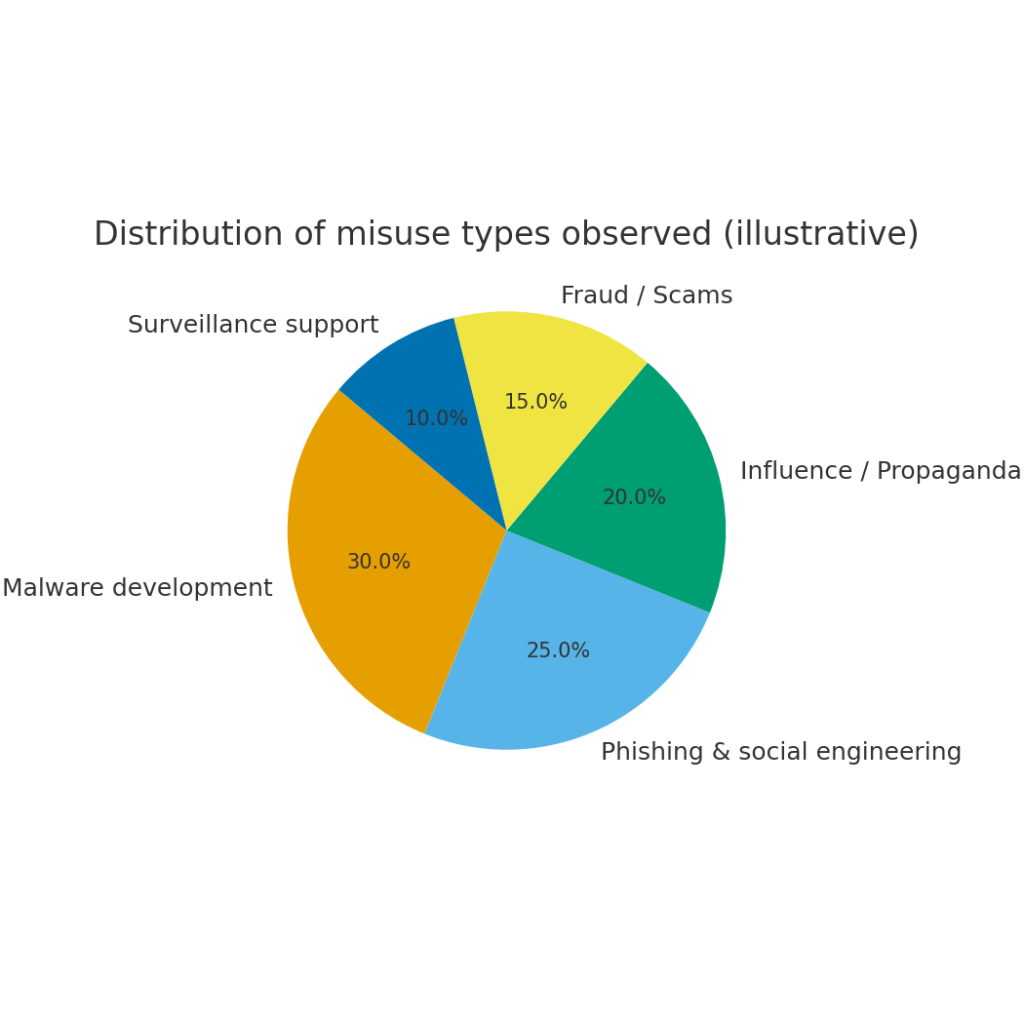
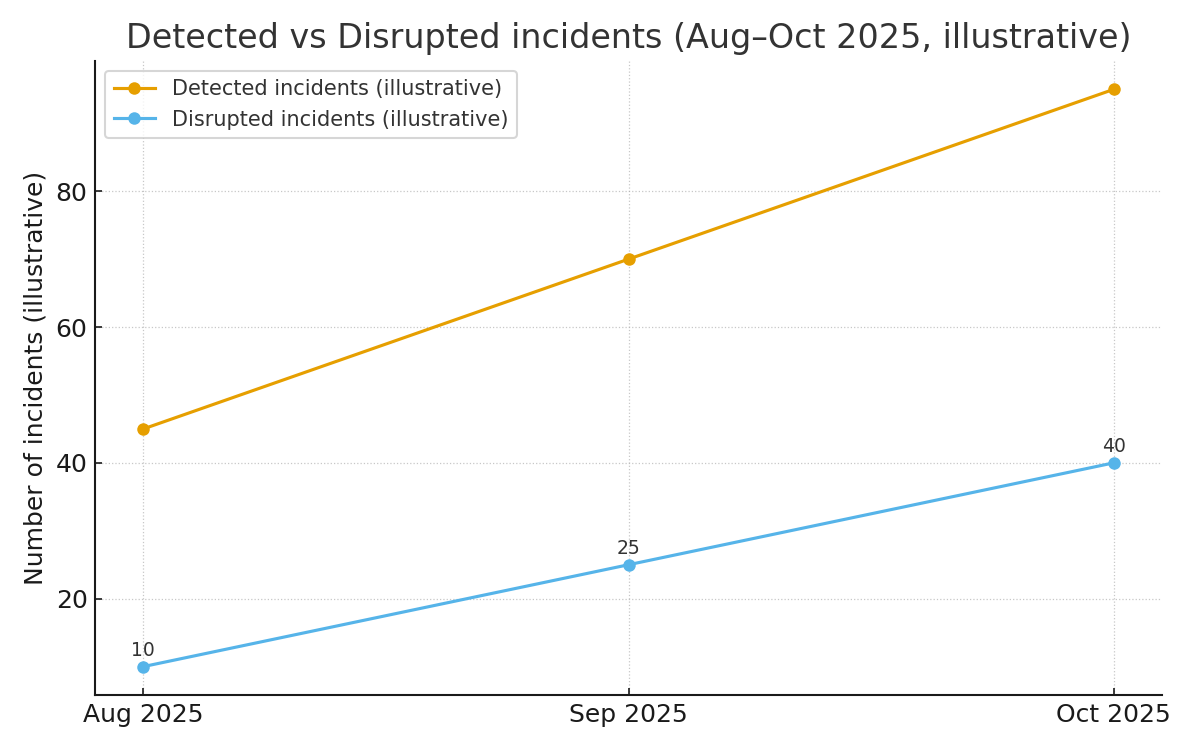
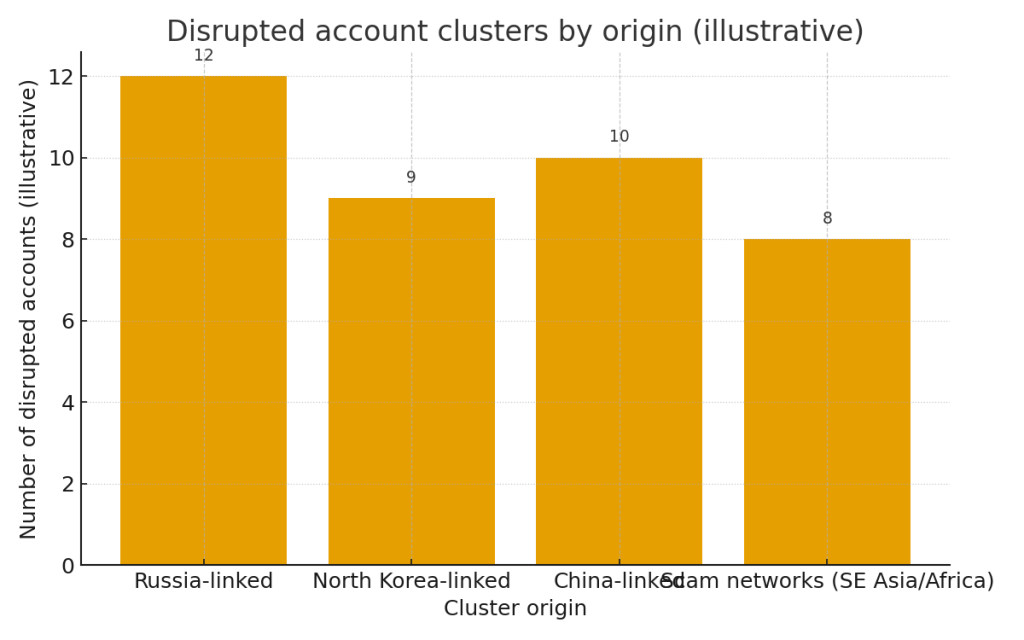
Иллюстрации и что они показывают
(Скачайте изображения выше.)
- Disrupted account clusters by origin — показывает схему распределения заблокированных/дисквалифицированных аккаунтов по происхождению (иллюстративные числа). Это даёт понимание, какие регионы чаще использовались для конкретных злоупотреблений.
- Distribution of misuse types — наглядно демонстрирует доли различных злоупотреблений: malware dev, phishing, influence ops, fraud и surveillance. Это помогает приоритизировать контрмеры.
- Detected vs Disrupted incidents timeline — примерная динамика количества обнаруженных инцидентов и числа инцидентов, где OpenAI предпринял активные действия по блокировке (Aug–Oct 2025). Она показывает растущий тренд активности и растущую способность платформы реагировать.
Интересные факты и наблюдения
- Злоумышленники адаптируются: в одном случае группа вручную или через модель убирала длинные тире (em-dashes) из контента, поскольку обсуждение в сети сделало эти символы индикатором ИИ-генерации. Это пример того, как операторы меняют стиль, чтобы избежать детекции.
- Anthropic и другие игроки также развивают инструменты для аудита и стресс-тестов моделей (пример — Petri), что указывает на возрастающий спрос на инструменты красной команды для ИИ.
Практические рекомендации для команд безопасности и провайдеров моделей
- Контекстный мониторинг и корреляция сигналов — поиск похожих запросов, многоразовых аккаунтов, повторной отладки кода по времени и перекрёстная корреляция с внешними каналами (Telegram, GitHub) помогают обнаружить persistent misuse.
- Ограничение tool-use и поэтапный доступ — вводите уровни прав для работы с генерацией кода: простые ответы — доступны, а сборочный инструмент (возможность генерировать большие блоки кода) — после дополнительной верификации.
- Встроенная валидация кода — проверять автоматически сгенерированный код на сигнатуры obfuscation, suspicious API calls, exfiltration patterns.
- Red-team для ИИ — регулярные тесты с использованием инструментов типа Petri или внутренних аудитов помогут выявить слабые места.
Прогнозы: чего ждать в ближайшие 6–18 месяцев
- Рост числа автоматических аудиторских инструментов. Конкурирующие компании и академические группы будут выпускать инструменты для автоматизированного тестирования моделей и обнаружения злоупотреблений (больше Petri-подобных проектов).
- Более изощрённые обходы детекции. Участники злоупотреблений станут всё более тактически гибкими: изменение стиля, многошаговые запросы, распределение запросов по множеству аккаунтов. Детекция станет cat-and-mouse.
- Регуляция и прозрачность платформ. Ожидайте больше требований к провайдерам LLM по прозрачности модерации, отчетности об инцидентах и сотрудничеству с правоохранительными органами.
- Интеграция защит в CI/CD и секьюрити-стек. Автодетекторы и code-scanners будут интегрироваться в DevSecOps как стандарт, чтобы перехватывать вредоносный код ещё до деплоя.
Вывод
Дело OpenAI по прерыванию активности злоумышленников показывает две вещи: во-первых, модели действительно дают новые возможности для злоупотреблений; во-вторых, провайдеры моделей уже приобретают инструменты и практики для обнаружения и вмешательства. Это начало серьёзной отраслевой борьбы — и пока что преимущество остаётся за теми, кто быстрее внедрит комплексные детекционные и превентивные меры, включая сочетание автоматизированных фильтров, анализа поведения и человеческого контроля.