Как нейросети улучшают обнаружение веб-атак в реальном времени
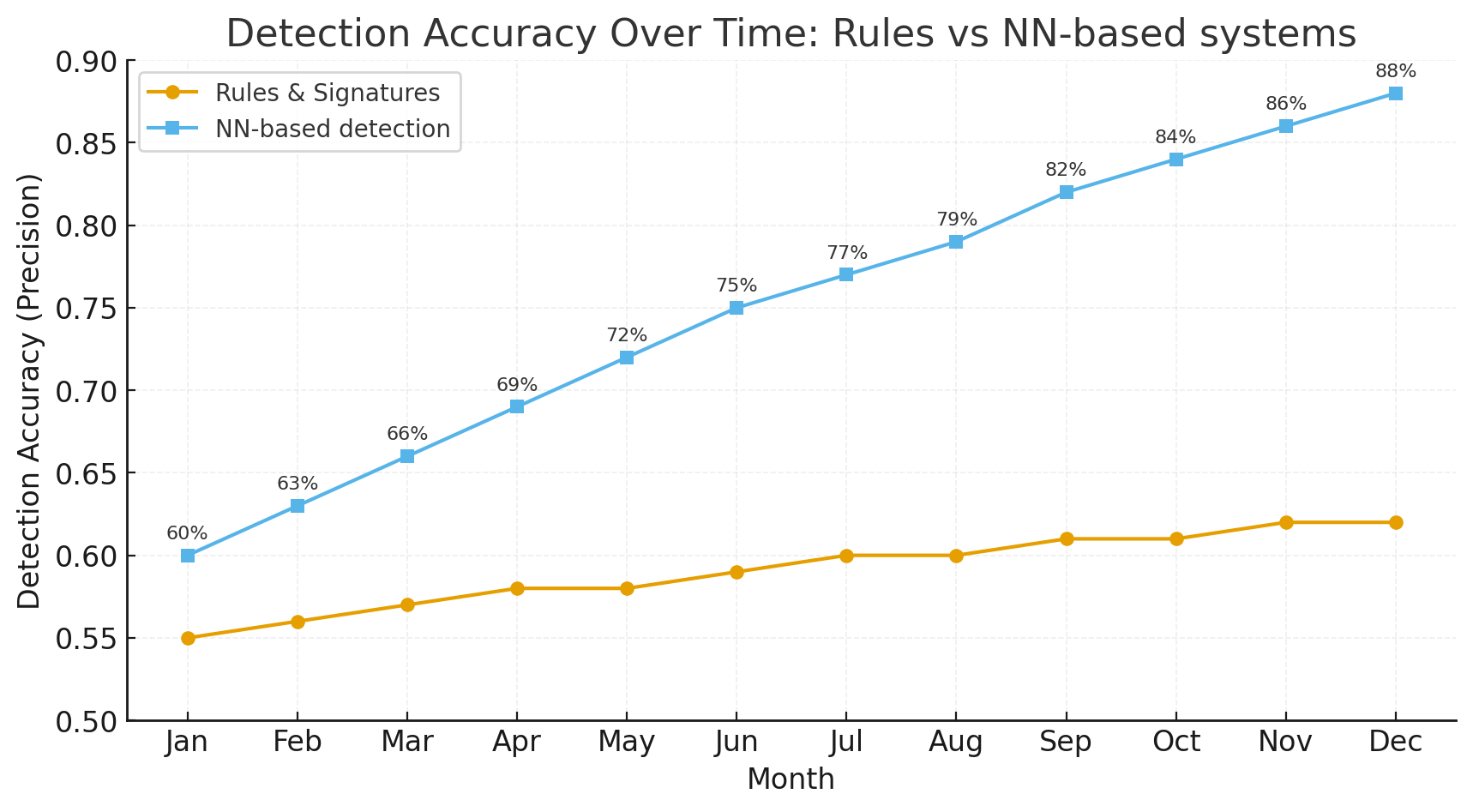
Веб-атак становится всё больше: от массовых сканирований и брутфорс-кампаний до целенаправленных атак с использованием цепочек поставок и web-shell. Традиционные правила и сигнатуры — важная часть защиты, но они часто запаздывают и плохо справляются с новым поведением. Нейронные сети (NN, deep learning) добавляют контекстно-чувствительный уровень: они умеют выявлять аномалии в сложных временных паттернах, моделировать поведение пользователей и агентов, и — при грамотной интеграции — существенно сокращать время обнаружения и шум в тревогах.
В этой статье мы подробно разберём подходы на базе нейросетей для real-time обнаружения веб-атак, архитектуры и алгоритмы, практики построения поведенческих моделей, методы уменьшения false positives и операционные нюансы внедрения в SecOps-процессы.
Почему нейросети — не «мода», а практический инструмент
Классические механизмы: WAF, статические правила, сигнатуры IDS/IPS — хорошо ловят известное и воспроизводимое. Но современные атаки требуют:
- обработки многомерных потоков телеметрии (логов веб-серверов, сетевых сессий, поведенческих событий),
- поиска сложных аномалий во временных рядах,
- нахождения скрытых корреляций между событиями (например, редкое сочетание заголовка User-Agent + последовательность URL → эксплойт),
- гибкой адаптации к новым паттернам без ручного написания правил.
Нейросети дают преимущества:
- Выявление сложных нелинейных паттернов (RNN, Transformer, GNN).
- Обучение прямо из сырых последовательностей событий (вместо ручной фичеинжиниринга).
- Онлайн-обновление / continual learning для быстрого реагирования на новые векторы атак.
- Умные ансамбли: NN + правила + эвристики = меньший шум.
Основные архитектуры и алгоритмы для real-time детекции
Ниже — перечень часто используемых архитектур и почему их выбирают.
1. Autoencoder / Variational Autoencoder (VAE)
Идея: обучается восстанавливать нормальное поведение; аномалии дают большой рекостанструкт.ошибку.
Применение: детекция аномалий в потоках (например, векторы признаков сессии).
Плюсы: не требует меток (unsupervised).
Минусы: чувствителен к дрейфу данных; беден в объяснимости.
2. LSTM / GRU / RNN
Идея: моделируют последовательности (порядок запросов, тайминги).
Применение: выявление необычных последовательностей запросов или поведений пользователей/агентов.
Плюсы: естественны для временных рядов.
Минусы: могут быть медленней в inferencing по сравнению с feed-forward; проблема долгой памяти для очень длинных сессий.
3. Transformer-based models
Идея: внимание (attention) лучше улавливает долгосрочные зависимости и связи между удалёнными элементами последовательности.
Применение: анализ сложных сессий, RAG-подходы к верификации событий.
Плюсы: сильны в моделировании контекста.
Минусы: вычислительные расходы; требует оптимизаций для real-time (distillation, quantization).
4. Graph Neural Networks (GNN)
Идея: строят графы взаимодействий (IP ↔ user ↔ session ↔ endpoint) и учатся предсказывать аномалии на узлах/ребрах.
Применение: обнаружение lateral movement, компрометации аккаунтов, скоординированных атак.
Плюсы: естественно моделируют связи и распространение атаки.
Минусы: графы нужно строить и поддерживать в near-real-time; сложнее масштабировать.
5. Contrastive / Self-Supervised Learning
Идея: учимся выделять нормальные представления без меток, затем аномалии — отклонения.
Применение: когда меток мало или они устаревают.
Плюсы: сильны для нестационарных сред.
Минусы: требуют тщательной инженерии позитив/негатив пар.
6. Hybrid systems (Rules + ML + NN)
Идея: классические правила покрывают очевидное; ML/NN — сложные случаи; orchestration решает, что исполнять.
Применение: production-ready защита — позволяет снизить FPR и обеспечить предсказуемость.
Плюсы: баланс между объяснимостью и мощью NN.
Минусы: orchestration добавляет сложность.
Поведенческий анализ (Behavioral Analytics): что именно моделируем
Поведенческий анализ — это основа для надежной детекции. Что моделируют нейросети?
- Сессии пользователей / агентов — последовательности URL, методы (GET/POST), тело запросов, заголовки, тайминги между запросами.
- Паттерны входа в систему — частота попыток логина, географические аномалии, длина сессии.
- Шаблоны взаимодействия с формами — скорость ввода, последовательность полей, повторные отправки.
- Аномалии пользовательского интерфейса — клики/hover/textarea behavior (для front-end instrumentation).
- Сетевая и прикладная корреляция — соединение между IP, ASN, ранее замеченными поведениями; графы взаимосвязей.
Ключевой мыслью является не «одно событие = атака», а «редкая комбинация событий по времени и отношению = подозрение».
Построение признаков (feature engineering) для NN: лучшие практики
Нейросети снижают необходимость ручного фичеинжиниринга, но грамотный набор признаков всё ещё важен:
- Сокращённые представления запросов: хэши путей, n-gram заголовков, embedding текста (для тела/параметров).
- Временные признаки: delta между запросами, distribution of inter-arrival times.
- Поведенческие агрегации: среднее число запросов на сессию, уникальные endpoints, entropy of headers.
- Сетевая телеметрия: ASN, geolocation, TLS fingerprint.
- Результаты детерминантных проверок: наличие known bad URL, отклонение от baseline.
- Псевдо-labels: weak labels из правил для semi-supervised обучение.
Для текстовых полей body/params удобно использовать pre-computed embeddings (sentence / param embeddings) и подавать их в NN как компактные векторы.
Unsupervised / semi-supervised vs supervised подходы
- Supervised (если есть метки): дает высокую точность, но метки дорогие и быстро устаревают. Подходит для хорошо изученных threat-model’ей.
- Unsupervised / Anomaly detection: автоэнкодеры, 부クラстерный анализ — хороши для «новых» векторов атак.
- Semi-supervised / Weak supervision: комбинируем сигнатуры/правила для генерации псевдо-меток, дообучаем NN. Эффективен на старте.
В production обычно применяют гибрид: правило/сигнатура → pseudo-label → NN → human validation → retrain.
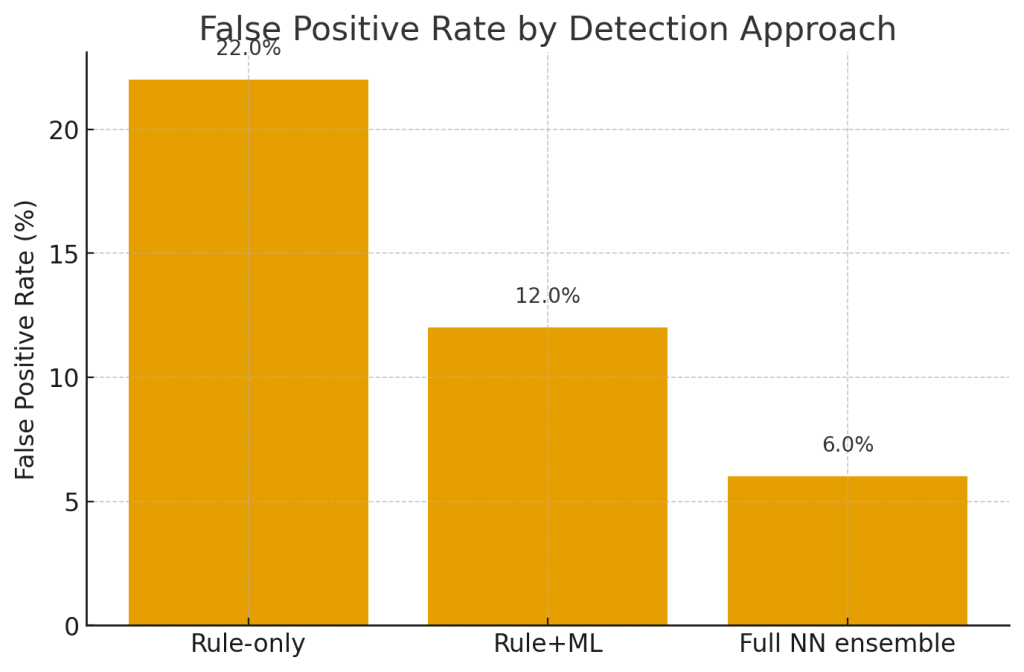
Как снизить false positives (практическая часть)
False positives (FP) — главный operational pain. Они переводят SecOps в режим пожарной борьбы и убивают доверие к системе. Вот рабочие методы для уменьшения FP при использовании NN.
1. Многослойная проверка (multi-stage triage)
- Stage 0 (fast rules): простые проверки (blacklist/whitelist, rate limits).
- Stage 1 (light ML): cheap models / small NN с низким latency дают initial score.
- Stage 2 (heavy NN + RAG): для high-risk случаев запускать полнофункциональную модель и retrieval (логи, исторические данные).
- Stage 3 (human): если score в серой зоне — человек решает.
Такой pipeline сокращает число дорогостоящих вызовов и уменьшает шум.
2. Калибровка и threshold tuning
- Калибруйте вероятности модели (Platt scaling, isotonic regression) чтобы score→prob корректно отражал риск.
- Подбирайте пороги на основе business-metrics: сколько false positives допустимо при заданной скорости обнаружения.
3. Объяснимость (explainability)
- Возвращайте reasons/feature-contributions (SHAP, attention highlights, reconstruction error breakdown).
- Пояснения помогают быстрым решениям при ручной проверке и снижают override.
4. Feedback loop & human-in-loop retraining
- Все ручные решения (approve/reject) логируйте и используйте для регулярного дообучения.
- Автоматизируйте pipeline retrain: weekly/monthly, с валидацией на holdout.
5. Ensembling & rule fusion
- Комбинируйте несколько моделей (temporal model + graph model + text classifier) — ансамбли уменьшают variance.
- Пусть правило с высокой достоверностью (например, known malware hash) доминирует над NN в некоторых сценариях.
6. Contextual bandit / adaptive thresholds
- Для разных сегментов (VIP users, partner IPs) ставьте свои пороги.
- Используйте contextual bandit подход для автоматического выбора действия (block, alert, hold) с оптимизацией бизнес-функции.
7. Simulation and shadow mode
- Запускайте модель в shadow/monitoring режиме, собирайте false positives и tune thresholds before enforcement.
Верификация и борьба с drift (дрейф моделей)
Дрейф — естественная проблема: поведение легитимных пользователей меняется, так же как и методы атакующих.
Практические меры:
- Continuous monitoring: следите за distribution shift (KS test) по ключевым признакам.
- Data versioning: сохраняйте snapshot’ы данных со временем (feature store).
- Scheduled retrain: регулярные переобучения (например, weekly) с валидацией.
- Canary model deployment: roll-out на долю трафика и сравнение метрик (FPR, TTD).
- Adversarial testing: периодические red-team испытания.
Оценка эффективности: какие метрики важны
SecOps/CTO/SRE должны смотреть набор KPI, включая:
- Precision, Recall (или precision@k): баланс между FP и FN.
- False Positive Rate (FPR) и False Negative Rate (FNR) (важно отслеживать оба).
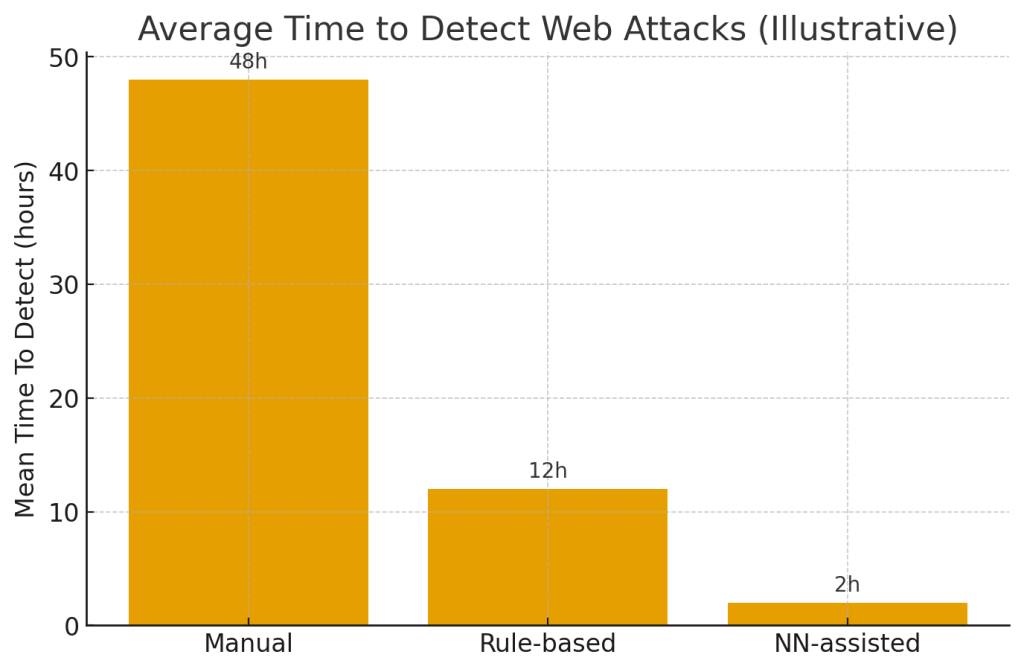
- Mean Time To Detect (MTTD): среднее время обнаружения инцидента. Цель — минимизировать.
- Mean Time To Respond (MTTR): от триггера до remediation.
- Containment rate: % атак остановленных автоматически.
- Operational cost: токены/compute + человеческие часы на обработку тревог.
- User impact metrics: % легитимных транзакций, помешанных автоматикой.
Интересный подход — оценивать cost of false positive (в человеко-часах и lost revenue) и оптимизировать модель с учётом этих затрат.
Real-time требования: latency, throughput, scaling
Для реального времени нужно учитывать:
- Latency budget: для inline защит (WAF) задержка должна быть минимальной (<10–50 ms в идеале). Для async анализа допускается 100s ms–seconds.
- Throughput: система должна обрабатывать пиковые нагрузки (всплески трафика). Обычно применяют horizontal scaling и batching.
- Model optimization: distillation, quantization, pruning, TensorRT/ONNX Runtime для сокращения latency.
- Edge vs Cloud: lightweight models на edge (или CDN/edge workers) для первичной фильтрации; heavy models в облаке для deeper analysis.
- Circuit breakers & fallback: при перегрузке временно откатывайте на правила или упрощённые модели.
Архитектура интеграции в production (пример)
- Ingest layer: Nginx / CDN / edge worker собирает запросы, headers, body (или hash), минимизирует PII.
- Feature computation: быстрые агрегаты по сессии, embedding запросов в real-time feature store.
- Triage service (low latency): lightweight model → score.
- Orchestrator: решает маршрут (block, challenge, enrich).
- Enrichment: глубокая модель, RAG (исторические логи), WHOIS, reputation.
- Decision engine: правила + ensemble → action.
- Human queue: интерфейс для аналитиков с explainability data.
- Feedback pipeline: все результаты — в training dataset и monitoring.
Примеры конкретных use-cases (иллюстративно)
A. Автоматическая блокировка сессий брутфорс-атак
- LSTM отслеживает pattern попыток ввода паролей; при отклонении от baseline → throttle + captcha. Результат: снижение атак на 70–90% в пилотах (оценочно).
B. Защита contact-form от эксплойтов и фишинга
- Text-embedding + classifier помечают сомнительные формы; при high risk → откладывается публикация и уведомление модератора.
C. Выявление скоординированных ботов
- GNN выявил кластер IPs/UA, которые посещают разные аккаунты в одно и то же время → блокирование по графовой оценке.
Interesting facts & industry-level observations (контекст)
- Атаки на веб-слой остаются ведущей причиной компрометаций: по разным отраслевым обзорам, значительная доля (в диапазоне 40–70% по оценкам разных аналитиков) инцидентов начинается с веб-эксплойта или уязвимости на веб-сайте. (Оценки варьируются; используйте свои telemetry и threat feeds для точной картины.)
- Human analysts burn-out: SOC команды тратят большое время на triage — сокращение false positives даже на 20–30% резко повышает скорость реагирования.
- LLM/NN помогают ускорять triage, но сами по себе требуют governance — объяснимость и audit trail критичны для доверия.
- Cost tradeoffs: стоит измерять не только уже сэкономленные часы инженеров, но и долгосрочные затраты на поддержание моделей (data labeling, retrain) — иногда simple heuristics + ML hybrid выигрывают по ROI.
(важно: приведённые выше проценты и эффекты — ориентировочные; конкретные результаты зависят от окружения и качества данных).
Практические рекомендации для SecOps/CTO/SRE: пошаговый план внедрения
Шаг 0 — оценка readiness
- Инвентаризируйте источники логов, latency constraints, и текущие правила.
- Оцените доступность labeled data.
Шаг 1 — Proof of Concept (2–6 недель)
- Соберите набор транзакций/сессий (мин. 10–100k событий).
- Постройте baseline: simple rules → anomaly detector (autoencoder) → evaluate precision/recall.
- Запустите в shadow mode.
Шаг 2 — Iteration & hybridization
- Добавьте sequence model (LSTM/Transformer) и graph features.
- Обучите ensembling model и введите staged triage (fast vs deep).
Шаг 3 — Production hardening
- Оптимизация модели (quantization), latency testing, canary rollout, SLOs.
- Объяснимость: SHAP / attention highlights / reasons engine.
Шаг 4 — Operationalize
- Continuous monitoring, retrain schedule, red-team tests, response playbooks.
- SLA для false positives handling и human review.
Шаг 5 — Governance
- Policy: who can change model, logging retention, privacy rules, audit trails.
Common pitfalls и как их избежать
- Поймать «all-the-things» подходом — попытка детектировать всё сразу. Лучше фокусироваться на high-impact сценариях.
- Недооценка затрат на data ops — сбор, очистка, хранение и метки стоят дорого; планируйте бюджет.
- Игнорирование explainability — аналитики не доверяют «чёрным ящикам», если нет объяснений.
- Перегрузка SecOps тревогами — tune thresholds, staged triage и feedback критичны.
- Неправильная посадка на model updates — автоматические апдейты без QA — риск.
Заключение
Нейросети делают обнаружение веб-атак в реальном времени более чувствительным к сложным и новым паттернам, чем это возможно с одними лишь правилами. Ключ к успеху — не примитивное «заменить правила на NN», а грамотное сочетание: быстрые правила для очевидных кейсов, lightweight-модели для triage, и тяжёлые deep-models для глубокого анализа с human-in-loop. Правильная инженерия фич, способность к непрерывному обучению, explainability, и операционная дисциплина (shadow mode, canary, retrain pipelines) позволяют снизить false positives, сократить MTTD/MTTR и повысить эффективность SecOps.
Если вы CTO или Head of SecOps, начните с малого: определите 1–2 высоко-приоритетных сценария (например, предотвращение брутфорса и защита contact-forms), соберите данные, запустите shadow pilot и измеряйте экономику (hours saved vs model ops cost). Затем масштабируйте решения постепенно, внедряя графовые и sequence-модели там, где они дают реальную ценность.