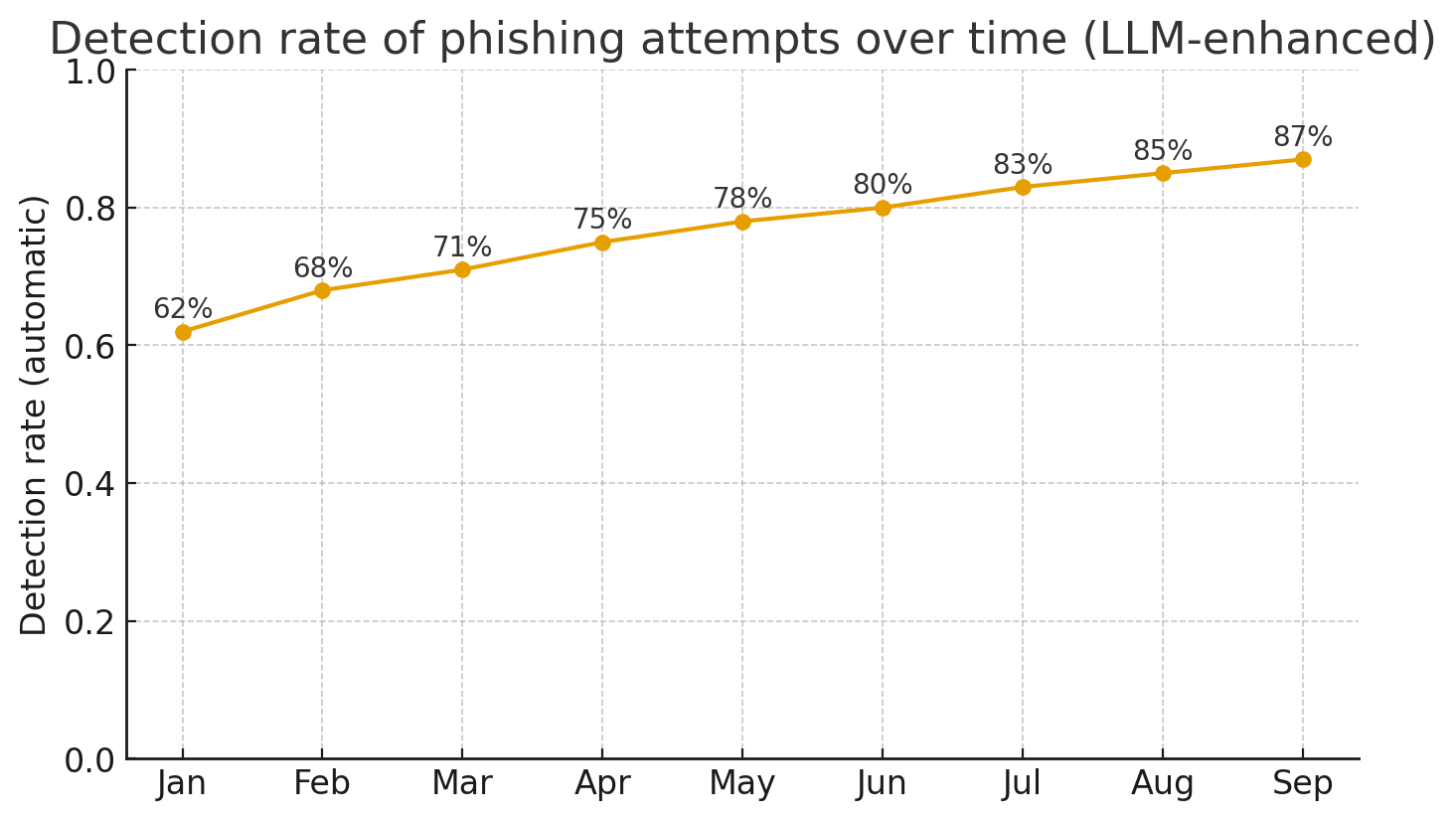
Фишинг через веб-формы и страницы «Контакты» остаётся одним из простых и эффективных способов компрометации организаций: злоумышленник отправляет обманные сообщения, подменяет поля формы или использует заполнение формы для доставки вредоносных ссылок и запросов на передачу данных. Большие языковые модели (LLM) стали новым инструментом в арсенале защиты: они умеют понимать контекст, выявлять тонкие языковые паттерны и помогать принимать взвешенные решения в реальном времени. В этой статье — практические подходы, как LLM помогают снижать риск фишинга на веб-формах и контактных страницах.
Чем LLM лучше классических правил
Классические фильтры (регулярные выражения, черные списки ссылок, простые ML-классификаторы) хорошо справляются с очевидными кейсами, но легко ломаются при изменении формулировок. LLM:
- анализируют семантику сообщения, а не только ключевые слова;
- способны выявлять косвенные признаки социальной инженерии (настойчивость, принуждение к действию, необычная тональность);
- могут генерировать объяснимые выводы и подсказки для модератора в удобном виде.
Это не панацея — LLM хорошо комбинировать с детерминистическими проверками.
Где именно ставить LLM в потоке формы
- Client-side предварительная проверка (легкий фильтр): короткий LLM-вызов в браузере или edge для пометки подозрений до отправки — полезно для UX (показывать предупреждение пользователю).
- Server-side классификатор: основной этап оценки перед сохранением/обработкой запроса. Здесь модель получает полный контекст (поля формы, метаданные, IP, user agent, временные паттерны).
- Режим модерации / human-in-the-loop: если модель низкоуверена или оценивает высокий риск — ставим на ручную проверку.
- Post-processing & feedback: результаты модерации и реакции пользователя (например, жалобы) возвращаются в систему для дообучения/тонкой настройки.
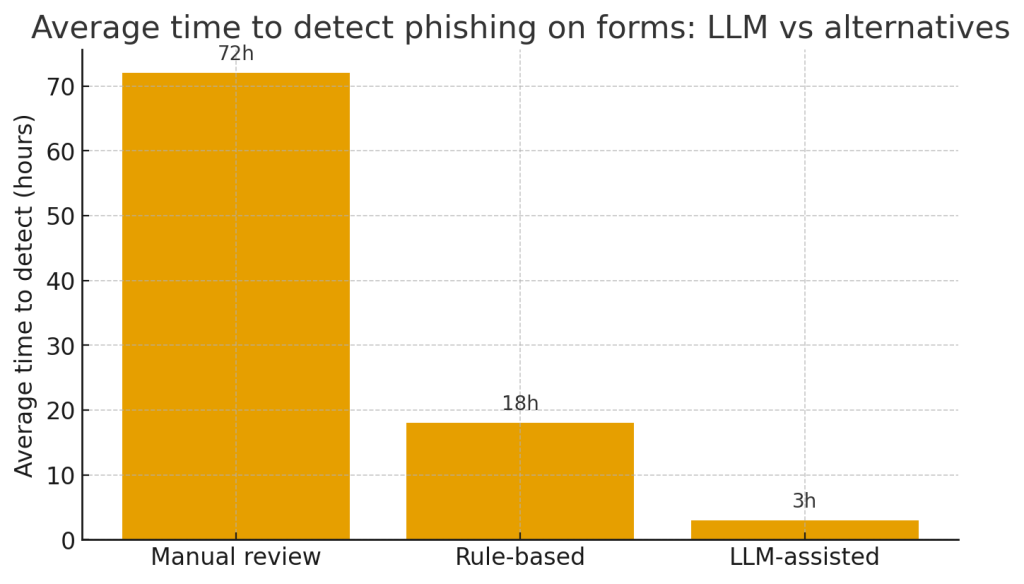
Практические паттерны применения
1) Семантическая классификация запросов
LLM классифицируют сообщение по категориям: нормальный запрос, рекламный спам, фишинговая попытка, социальная инженерия. Вы получаете не просто «флаг», а объяснение: какие фразы сработали и почему они подозрительны.
2) Детекция подозрительных ссылок и доменов
Модель проверяет ссылки в контексте сообщения: есть ли несоответствие между видимым текстом и реальным URL, используется ли сокращатель, встречаются ли признаки подделки домена (typosquatting). Комбинируйте с проверками WHOIS и базами безопасных/опасных доменов.
3) Анализ тональности и манипулятивных триггеров
Фразы вроде «немедленно», «срочно свяжитесь», «секретный способ» часто сопровождают фишинг — LLM умеют выявлять такие сигналы в контексте и учитывать редкость выражений.
4) Генерация объяснений для модераторов
Вместо сухого «флаг», LLM возвращает краткое обоснование: «Запрос просит перекинуть деньги, содержит сокращённую ссылку bit.ly и использует тон давления». Это ускоряет ручную проверку.
5) Автоматическая реакция и подсказки
Для входящих сообщений с сомнительным характером система может автоматически отправлять безопасный ответ: запросить подтверждение, оповестить о том, что запрос будет проверен, предложить альтернативный канал (звонок). Это снижает вероятность немедленного вреда.
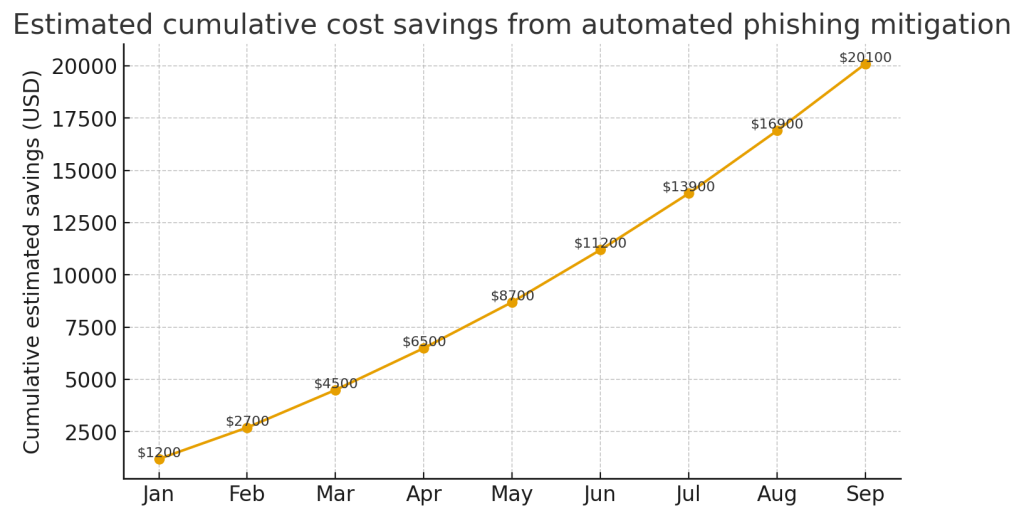
Пример структуры вывода (JSON)
Ниже — упрощённый пример того, что модель может вернуть серверу после анализа:
{
"risk_score": 0.87,
"label": "phishing",
"reasons": [
"использует срочный тон ('срочно', 'немедленно')",
"содержит сокращённую ссылку bit.ly/xyz",
"адрес отправителя не совпадает с доменом компании"
],
"recommended_action": "hold_for_review",
"extracted_links": ["bit.ly/xyz"]
}
Такой формат легко интегрировать в пайплайн модерации.
Метрики и «границы» для принятия решений
- False Positive Rate (FPR): важно не мешать реальным клиентам — настраивайте порог риска.
- Mean Time to Review для помещённых на ручную проверку запросов.
- Containment rate — % фишинговых сообщений, отловленных автоматически.
A/B-тестируйте пороги и реактивные ответы.
Важные инженерные и этические соображения
- Приватность данных: формы часто содержат PII. Минимизируйте отправку в сторонние модели: либо используйте приватные/он-премис модели, либо применяйте redaction/псевдонимизацию.
- Пояснимость: регистрируйте, почему модель приняла решение — это поможет при спорах и разбирательствах.
- Устойчивость к обходам: злоумышленники могут пытаться «обмануть» модель. Периодические red-team тесты и обновления промптов обязательны.
- Юридические аспекты: уведомляйте пользователей о том, что сообщения могут проходить автоматическую проверку (в политике конфиденциальности).
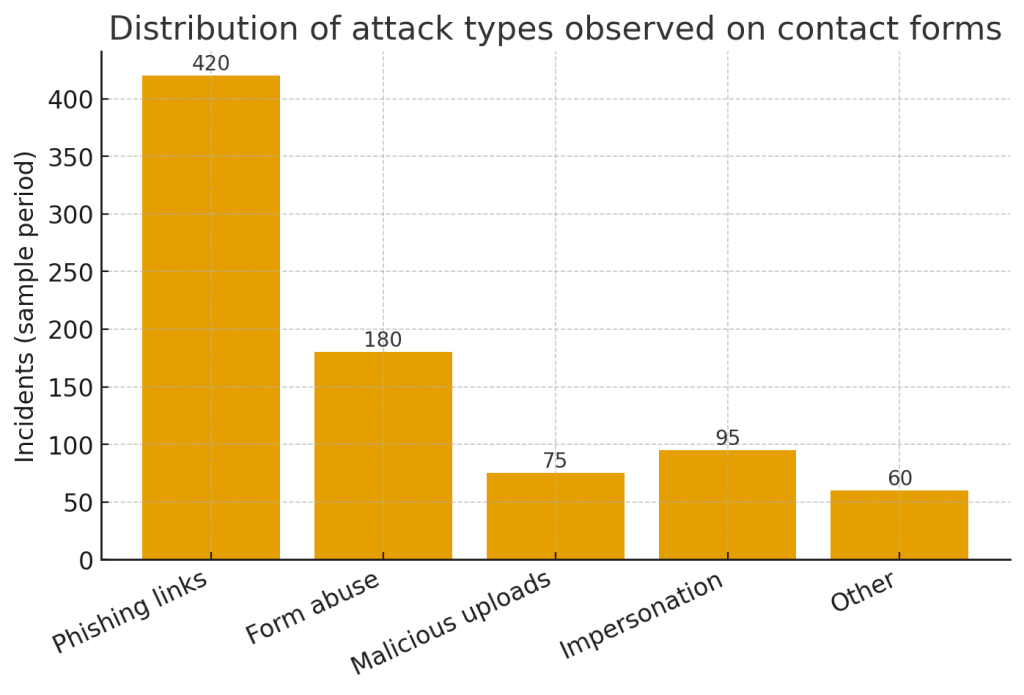
Ограничения LLM и лучшие практики
- LLM — мощный, но сто́ит комбинировать его с сигнатурами, черными списками и сетевыми фильтрами.
- Для критичных решений (платежи, смена доступа) — обязательный human-in-the-loop.
- Постоянно собирайте реальные «ошибочные» кейсы: дообучение на собственном телеметрическом датасете повышает точность.
Короткая дорожная карта внедрения (3 шага)
- Пилот: подключите LLM для анализа входящих форм в shadow-режиме (не блокируя) и собирайте метрики.
- Нормирование: установите пороги риска и цепочку реакции (авто-ответ, удержание, ручная проверка).
- Масштаб: интегрируйте с SIEM/EDR, добавьте фидбек-петлю для дообучения и регулярных red-team проверок.
Итог: LLM дают гибкий и контекстно-чувствительный слой защиты для веб-форм и контактных страниц: они помогают отличать искренние запросы от социальной инженерии, подсказывают модераторам и снижают скорость распространения фишинговых атак. При правильной архитектуре — с учётом приватности и ручных ворот — LLM становятся эффективным компонентом многоуровневой обороны сайта.