
Когда «код по настроению» ломает систему: как vibe coding вредит безопасности
«Vibe coding» — практика, когда разработчики полагаются на LLM (модели больших языков) для генерации кода и принимают результат с минимальной ручной проверкой — ускоряет прототипирование и снижает порог входа. Но та же самая кратчайшая дорога увеличивает и концентрирует риски безопасности: модели воспроизводят небезопасные шаблоны в масштабе, упускают системные предпосылки, могут способствовать утечкам секретов и создавать хрупкие, трудноотслеживаемые поверхности атаки. В продакшне использование vibe coding без жёстких ограничений и процессов наблюдения приводит к измеримым и устранимым рискам.
Ключевые утверждения этой статьи опираются на отраслевые исследования и отчёты, в которых фиксируется высокий уровень дефектов в сгенерированном ИИ-коде и предупреждается о рисках попадания непроверенного кода в продакшн.
Что такое vibe coding?
Vibe coding — это подход, когда разработчик описывает желаемое поведение на естественном языке модели и затем принимает сгенерированный код без тщательной построчной проверки. Практика базируется на итерациях «попросил — запустил — поправил», а не на глубоком чтении и анализе исходников. Термин получил широкое распространение, когда разработческие рабочие процессы стали смещаться в сторону разговорного управления инструментами и агентами, где фокус смещается с исходного кода на поведение.
Ключевые признаки vibe coding:
- Взаимодействие «сначала текст», а не посимвольное кодирование.
- Быстрые итеративные циклы: генерируешь, запускаешь, наблюдаешь, уточняешь.
- Меньший упор на ручную проверку исходников; больше — на тестирование и поведение.
- Широкое использование ассистентов в редакторах и агентных генераторов кода.
Для прототипов и одноразовых скриптов это мощный подход, но он радикально отличается от традиционных практик, где код читают, ревьюят и защищают дизайном.
Почему vibe coding так быстро прижился
Причины популярности просты:
- Скорость и поток работы: разработчики отмечают значительное сокращение времени на прототипирование UI, glue-кода и скриптов.
- Пониженный порог входа: люди без глубоких навыков программирования могут создавать полезные инструменты.
- Доступность инструментов: редакторные агенты, сервисы «сделай приложение по тексту», интегрированные ассистенты — всё это делает разговорную генерацию кода практичной.
- Ускорённая экспериментальность: описать изменения на языке — проще, чем писать код вручную, поэтому гипотезы проверяются быстрее.
Однако те факторы, которые дают эту скорость, одновременно и создают риски: когда разработчик перестаёт внимательно читать код и полагается на «плавность» вывода модели, системные допущения и пограничные случаи проскакивают незамеченными.
Проблема безопасности в формуле
Традиционная безопасная разработка опирается на то, что люди пишут, читают и осмысляют код — именно этим часто предотвращаются уязвимости. Vibe coding перемещает ответственность:
- От человеческого мышления → к статистической генерации: модели учатся по большому числу примеров, но не «понимают» модель угроз или конкретные условия среды выполнения, если их явно не указать и не проверить.
- От явного ревью → к implicit-тестированию: принятие кода часто основывается на успешном прохождении быстрых тестов и запуске, а не на безопасности исходников.
- От единичной проверки → к массовому воспроизводству: модель, породив один небезопасный паттерн, может воспроизвести его во множестве мест и проектов.
Результат: ошибки, которые человек бы заметил при внимательном просмотре, начинают распространяться в масштабе. Крупные аудиты и исследования подтверждают этот сдвиг.
Что показывают данные (исследования и отчёты)
Поставим это на эмпирическую основу.
- В одном крупном исследовании безопасности анализировали фрагменты кода, сгенерированные различными LLM, и обнаружили, что примерно 45% таких фрагментов содержали уязвимости, имеющие отношение к безопасности. Это не мелкая погрешность — это сигнал системного риска: почти половина фрагментов может внести уязвимость в кодовую базу, если её принять без контроля.
- Практические материалы инженеров и посты от вендоров подчеркивают типичные режимы отказа моделей и показывают, что безопасно-ориентированные шаблоны и подсказки уменьшают количество небезопасных генераций, но не устраняют проблему полностью.
- Рынок платформ для генерации кода столкнулся с операционными вызовами: тяжёлое использование и неожиданные инциденты по безопасности привели к перерасходу ресурсов и повышенной текучести у ранних пользователей. Это показывает, что помимо качества кода есть и бизнесовые риски внедрения без зрелых процессов.
Эти данные демонстрируют и масштаб проблемы, и то, что пути её смягчения существуют, но пока ещё не стали общепринятыми.
Пять конкретных векторов угроз, связанных с vibe coding
Ниже — практичные способы, как именно vibe coding увеличивает поверхность атаки и вероятность инцидентов.
1. Массовое воспроизведение небезопасных паттернов
Модели обучаются на гигантских наборах кода, где встречаются небезопасные примеры. Без явных ограничений модель с высокой вероятностью воспроизведёт простые, но уязвимые практики (например, конкатенацию строк в SQL без параметризации, отсутствие валидации входных данных). Если разработчик принимает код «как есть» и быстро деплоит его, один и тот же паттерн может появиться во многих сервисах.
Почему опасно: один небезопасный шаблон, размноженный по микросервисам, создаёт множественные точки входа для атак.
Митигировать: использовать безопасные шаблоны в подсказках и автоматические проверки в CI.
2. Отсутствие учёта системных предпосылок и threat model
Сгенерированный фрагмент выполняет локальную задачу, но не знает контекста окружения, модели прав доступа, особенностей инфраструктуры. Код может корректно работать при локальном тесте, но быть небезопасным в распределённой системе (например, раскрывать внутренние API или давать избыточные привилегии).
Почему опасно: уязвимости часто возникают не из синтаксиса, а из несогласованности архитектурных допущений.
Митигировать: внедрять проверку на уровне архитектуры и тесты, замеряющие соответствие threat model.
3. Утечки секретов и неправильное обращение с учётными данными
Разработчики, экспериментируя, иногда вставляют реальные строки подключения или ключи в подсказки; модели могут «вырости» подстановки или логировать примеры, а сторонние сервисы — хранить логи промптов. Это ведёт к риску утечек, особенно если поставщик сервиса не гарантирует приватность промптов.
Почему опасно: утекшие секреты приводят к немедленным взломам и утечкам данных.
Митигировать: применять клиентские санитайзеры, детекцию секретов, и частные эндпоинты с контрактными гарантиями на хранение промптов.
4. Уязвимости через зависимости и цепочки поставок
LLM часто генерируют файлы зависимостей (package.json, requirements.txt) и могут выбрать удобные, но не аудитированные пакеты или устаревшие версии с известными CVE.
Почему опасно: зависимость с уязвимостью даёт путь для supply-chain атак.
Митигировать: автоматическое сканирование зависимостей, SBOM, запрещающие политики по пакетам.
5. Ускорение возможностей злоумышленников
Те же инструменты, что ускоряют разработчиков, позволяют злоумышленникам быстрее генерировать эксплоиты, создавать скрипты для автоматизации атак и исследовать уязвимости в коде. Исследования показывают, что AI-сопровождение сокращает время на разработку работающего эксплойта.
Почему опасно: инструменты повышают масштаб и скорость атак.
Митигировать: проводить red-team испытания, мониторить необычные шаблоны генерации и корректировать процессы защиты.
Иллюстративные кейсы из практики
Ниже — упрощённые (анонимные) примеры, как проблемы проявлялись в реальных проектах.
Сценарий A — «Быстрый плагин — постоянная дыра»
Команда сгенерировала плагин, который принимает пользовательские данные и пишет их в БД. Ассистент выдал код с конкатенацией SQL-строк ради простоты. Команда проверила плагин на тестовых данных и выпустила в продакшн. Позже аудит выявил, что плагин уязвим к SQL-инъекции, которую мог использовать любой пользователь с доступом к API. Уязвимость оказалась тривиальной и могла привести к утечке данных.
Причина: модель воспроизвела небезопасный паттерн; команда доверилась поведенческому тесту, не запустив SAST.
Сценарий B — «Секреты в промптах»
Инженер для генерации миграции вставил в подсказку полный connection string с паролем. Промпт был отправлен в облачный агент, и его лог оказался доступен у поставщика (в логе или снэпшоте). Позже этот лог попал в массу доказательной информации при юридическом запросе, что превратило инцидент в проблему соответствия требованиям и вызвало расследование.
Причина: отсутствие гигиены промптов и приватного коннектора.
Сценарий C — «Зависимости со житьём»
Стартап сгенерировал манифест npm и принял предложенные версии библиотек. Одна из выбранных библиотек оказалась с недавно объявленной критической уязвимостью. Команда полагалась на «шаблон» и пропустила стадию сканирования зависимостей.
Причина: отсутствие SBOM и правила vetting зависимостей.
Эти сценарии демонстрируют общий паттерн: принятие кода по поведению и быстрым тестам вместо тщательного анализа исходников и цепочек поставок.
Как уязвимости проявляются в мониторинге и инцидентах
Если vibe coding широко используется в организации, наблюдаются типичные сигнатуры в мониторинге:
- Увеличение числа инцидентов в первые недели после деплоя, так как генерация часто не покрывает пограничные кейсы.
- Повторяющиеся шаблоны уязвимостей в разных сервисах, поскольку модель воспроизводит одинаковые небезопасные конструкции.
- Неожиданные всплески телеметрии: ошибки из-за неподготовленных входных данных или исключений, указывающие на отсутствие защитных проверок.
- Проблемы соответствия: обнаружение секретов в логах, сторонних местах хранения промптов и т. п.
Команды безопасности должны иметь метрики и детекторы на эти явления, если vibe coding разрешён в компании.
Инженерные меры защиты: что реально помогает
Не существует единой панацеи; нужны многослойные меры. Ниже — практические, применимые техники, сочетающие автоматизацию и процессы.
A. Шаблоны подсказок, ориентированные на безопасность
Создавайте защищённые промпты с обязательными указаниями: «Используйте параметризованные запросы», «Нормализуйте и валидируйте входные данные», «Добавьте unit-тест, демонстрирующий попытку инъекции». Такие инструкции снижают вероятность генерации тривиально небезопасного кода.
B. Автоматические ворота в CI/CD
Каждый сгенерированный PR должен проходить SAST, сканирование зависимостей, обнаружение секретов и тесты с атаками (adversarial unit tests). Билд должен падать на критические находки.
C. Захват происхождения (provenance) и неизменяемые артефакты
Логирование точного промпта, версии модели и сгенерированного артефакта (или его хеша) для последующего аудита. Это позволяет понять, откуда пришла уязвимость, и кто её принял.
D. Человеческая проверка для рискованных артефактов
Классифицируйте код по рискам (сетевой код, авторизация, платежи) и потребуйте обязательную ревью безопасности перед merge для высоких категорий.
E. Инструменты защиты секретов и частные эндпоинты
Используйте локальные санитайзеры для промптов, никогда не вставляйте в подсказки реальные секреты, и по возможности применяйте приватные модельные эндпоинты с контрактными гарантиями на хранение промптов.
F. Политики по зависимостям и SBOM
Генерируйте SBOM для каждого проекта, запускайте policy-checks и запрещайте пакеты с известными CVE или неблагонадёжными провайдерами.
G. Снижение привилегий и ограничение поверхности атаки
Запускайте сгенерированный код с минимально необходимыми правами, сегментируйте сеть и требуйте эфемерных credentials для деплоя.
Эти меры вместе значительно уменьшают шанс того, что сгенерированный фрагмент превратится в критическую уязвимость.
Организационные меры и корпоративное управление
Технологии — важны, но без организационных правил риски останутся.
1. Политики: определите границы применения
Чётко пропишите, где разрешён vibe coding: только в песочницах, для внутренних инструментов, или в отдельных контролируемых областях. Применяйте автоматические запреты на merge при нарушении политики.
2. Обучение: сделайте промпты безопасными
Обучите инженеров правилам безопасного составления промптов, объясните разницу между «принимать поведение» и «принимать исходники», научите, как документировать предположения промптов.
3. Инструментирование: встройте безопасность в инструменты
Встроенные SAST, SBOM, обнаружение секретов — всё это должно работать прямо в потоке генерации кода (асcсистент → PR), чтобы фидбек был немедленным.
4. Метрики: измеряйте важное
Отслеживайте долю сгенерированных PR, в которых находят уязвимости, среднее время на исправление, долю PR, требующих ручной проверки. Эти KPI помогут выявлять регрессии.
5. Закупки и контроль поставщиков
Если вы используете внешние агентные сервисы — контракты должны фиксировать политику хранения промптов, приватность, условия инцидент-реакции и возможность приватных эндпоинтов. Провайдеры отличаются по этим параметрам, поэтому при выборе учитывайте юридические риски.
Практический план: как внедрить vibe coding безопасно (8 недель)
Если вы хотите использовать vibe coding и при этом ограничить риски, можно развернуть программу за ориентировочный срок в 8 недель.
Неделя 0–1: Политика и сфера применения
- Определите области, где vibe coding разрешён (песочницы, внутренние инструменты и т. д.).
- Составьте таксономию рисков и классифицируйте типы кода.
Неделя 1–2: Настройка инструментов
- Интегрируйте ассистента, чтобы он создавал PR в контролируемом репозитории.
- Добавьте pre-commit хуки для обнаружения секретов.
Неделя 2–4: CI/CD ворота безопасности
- Включите SAST, dependency scanning, unit-тесты с adversarial-кейсами.
- Настройте блокировку мержа при критических находках.
Неделя 4–6: Гигиена промптов и шаблоны
- Разработайте шаблоны промптов с требованиями безопасности.
- Скрипты, которые «спрашивают у модели» обязательные пункты: валидизацию входа, параметризацию запросов.
Неделя 6–8: Ручная проверка и метрики
- Введите обязательную ручную ревью для объектов высокого риска; соберите первоначальные метрики (процент флагов, время на исправление).
- Запустите red-team, использующий техники vibe coding для поиска уязвимостей в ваших пайплайнах.
Этот план итеративный — через 8 недель вы получите базовый цикл, который можно масштабировать и ужесточать.
Контрольный список: минимальные требования перед разрешением vibe coding
Перед разрешением vibe coding в любой среде обязательно:
- Контролируемая приватность промптов или приватные эндпоинты.
- SAST и сканирование зависимостей в CI для сгенерированных PR.
- Обнаружение и предотвращение утечек секретов на клиенте и в CI.
- Генерация SBOM для всех манифестов.
- Обязательная ручная проверка безопасности для критичных путей.
- Логирование происхождения (prompt, модель, версия).
- Ограничение привилегий для сгенерированного кода.
- Red-team упражнения, использующие vibe coding.
- Договоры с вендорами, гарантирующие обращение с данными и prompt-privacy.
- KPI по частоте обнаружений в сгенерированных PR и SLA на фиксы.
Это минимальный набор, превращающий экспериментальную практику в управляемый инструмент.
Визуализация проблемы (три иллюстративных графика)
Ниже — три иллюстративных графика, которые помогают объяснить масштаб проблемы и приоритеты для контроля. Эти визуализации сделаны для коммуникации риска и не претендуют на точность по конкретному исследованию — они агрегируют и синтезируют отраслевые наблюдения.
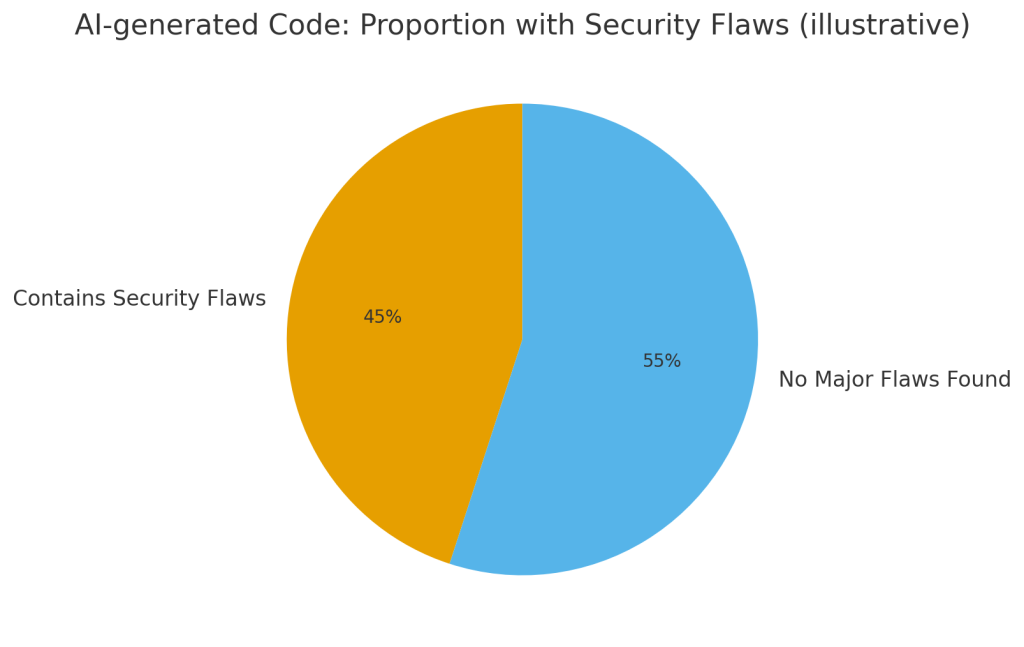
- Доля AI-кода с уязвимостями — крупное исследование показало ~45% фрагментов с проблемами. Это визуализируется в виде круговой диаграммы.
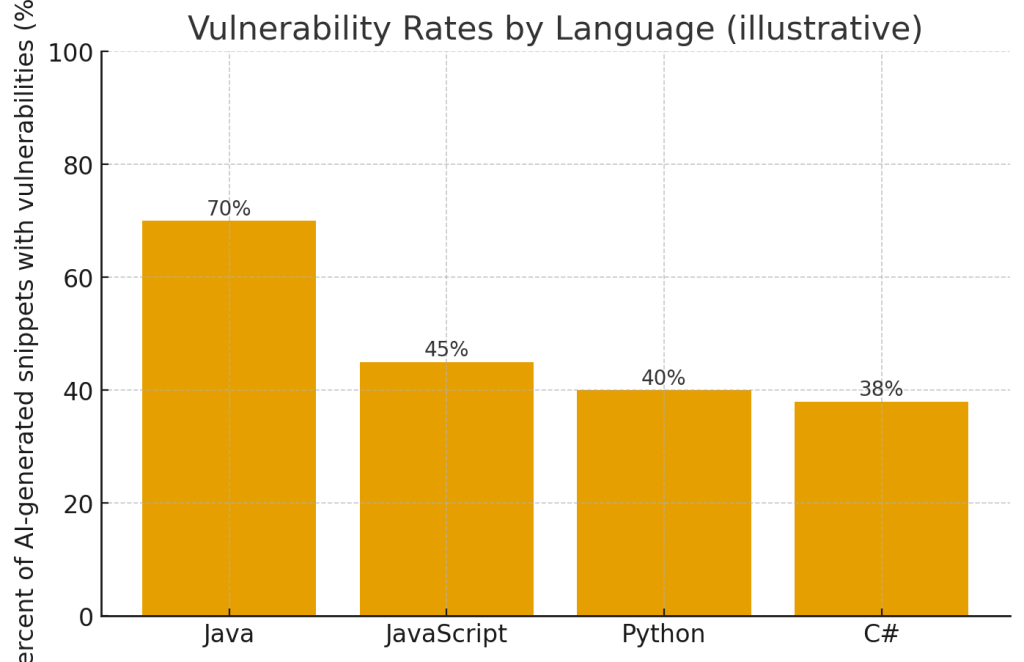
- Уровни уязвимостей по языкам (иллюстративно) — в некоторых образцах Java показывает высокую долю уязвимых фрагментов (~70%), Python/JS/C# — ниже, но значимо. Эта диаграмма подчёркивает, где особенно внимательны к зависимостям и валидации.
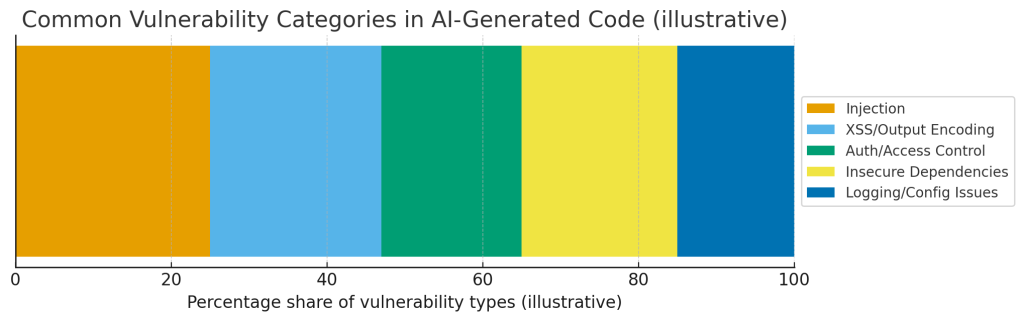
- Распределение типов уязвимостей в AI-коде (синтетическое) — например, injection, XSS/кодирование вывода, ошибки авторизации, небезопасные зависимости, проблемы с логированием/конфигом.
(Если нужно, я упакую эти графики в ZIP или PPTX и дам ссылку для скачивания.)
Приведение разработки и потока работы в баланс: как сохранить flow и не потерять безопасность
Vibe coding ценят за состояние «flow». Сохранить его, не жертвуя безопасностью, можно так:
- Встраивайте подсказки безопасности прямо в редактор: не блокирующие предупреждения с предложениями безопасных альтернатив.
- Делайте проверки быстрыми и «невидимыми»: локальные pre-commit SAST и мгновенные проверки, чтобы фидбек был незамедлительным и не ломал итерацию.
- Разрешайте быстрые приёмы для низко-рисковых задач (UI, стилистика), но жестко ограничивайте критичные подсистемы.
Цель — минимизировать трение и максимизировать защиту.
14 — Практические промпты и приёмы для более безопасных генераций
Ниже — рабочие паттерны промптов, которые помогают снизить риск:
- «Security-first» шаблон: «Сгенерируй код, использующий параметризованные запросы, выполняющий нормализацию входных данных, и добавь unit-тесты, демонстрирующие попытки инъекций».
- «Объясни, затем сгенерируй»: попросите модель кратко объяснить, как предложенный код защищает от атак, и перечислить предположения. Если объяснение поверхностно — потребуйте ревью.
- «Ветирование зависимостей»: «Предлагай только библиотеки со стабильной поддержкой и без известных CVE за последние 12 месяцев» — но всегда дополняйте это автоматическим сканированием, а не только доверием модели.
Эти приёмы уменьшают вероятность ошибок, но не заменяют автоматические проверки и экспертную оценку.
Ограничения доказательной базы и критический взгляд
- Исследования фиксируют высокую долю ошибок, но реальный ущерб зависит от того, где применяется код: throwaway-скрипт и платежный шлюз — разные уровни риска.
- Промпт-инжиниринг помогает, но не заменяет безопасность проектирования; модели склонны выдавать уверенные, но неверные утверждения.
- Вендоры различаются по возможностям приватности и опциям частного хостинга; это принципиально меняет риски утечек и ответственность за данные. При выборе провайдера учитывайте юридические и операционные детали.
Практические рекомендации, приоритетные действия
Если хотите получить выгоду от vibe coding и одновременно держать под контролем риски, начните с этого:
- Не разрешайте автоматическое принятие в продакшн. Любой код, затрагивающий чувствительные системы, должен проходить обязательную проверку.
- Инструментируйте весь жизненный цикл. От промпта до артефакта: логируйте, сканируйте, блокируйте.
- Стартуйте с низко-рисковых сценариев. Используйте vibe coding для прототипов и внутренних автоматизаций с ограничениями.
- Инвестируйте в автоматизацию. CI-ворота, сканирование зависимостей и обнаружение секретов быстро окупаются.
- Комбинируйте человеческое и автоматическое. Автоматические правила не заменят суждения человека в критичных случаях.
- Измеряйте и итеративно улучшайте. Ведите статистику по flaw-rate и снижайте её целенаправленно.
Эти шаги можно вводить поэтапно; вложение в практику безопасности будет значительно дешевле устранения инцидента в продакшне.
Источники и ссылки (обзорно)
Ключевые материалы и наблюдения, использованные в статье:
- Исследование, показавшее, что примерно 45% AI-сгенерированных фрагментов содержат уязвимости.
- Инженерные и вендорские публикации о техниках снижения риска через промпт-шаблоны и автоматизацию.
- Маркетинговые и аналитические материалы о развитии платформ для генерации кода и связанных операционных вызовах.
(Если нужно, могу подготовить аккуратный список ссылок и PDF-референсов.)
Финальная мысль
Vibe coding — мощный инструмент повышения продуктивности: он делает создание кода более доступным и ускоряет эксперименты. Но этот подход меняет модель угроз: он снимает часть человеческих фильтров, которые годами защищали софт-индустрию. Ответственный путь — сохранить скорость и креативность, но построить новые жёсткие ограждения: автоматические проверки, логирование происхождения, ручные ревью для критичных областей, и договорные гарантии при использовании внешних провайдеров. Тогда вы получите выгоду от технологий без необоснованного роста операционного риска.